IWAG Staff

Hello!
We want to start by thanking you for your patience and support during the bumpy event pass sales opening on the night of January 4th, 2025. Now that everything is back on track and the Community website is running smoothly, we’d like to share a behind-the-scenes look at what happened and how we resolved it.
In this post, we’ll walk you through the steps we took to identify, fix, and stabilize the issues we faced. While we’ll touch on some technical details, we’ll do our best to make everything easy to understand. Let’s dive in!
What Happened?
To explain what went wrong, we first need to give you a quick overview of how the Community website works. There are four key parts involved:
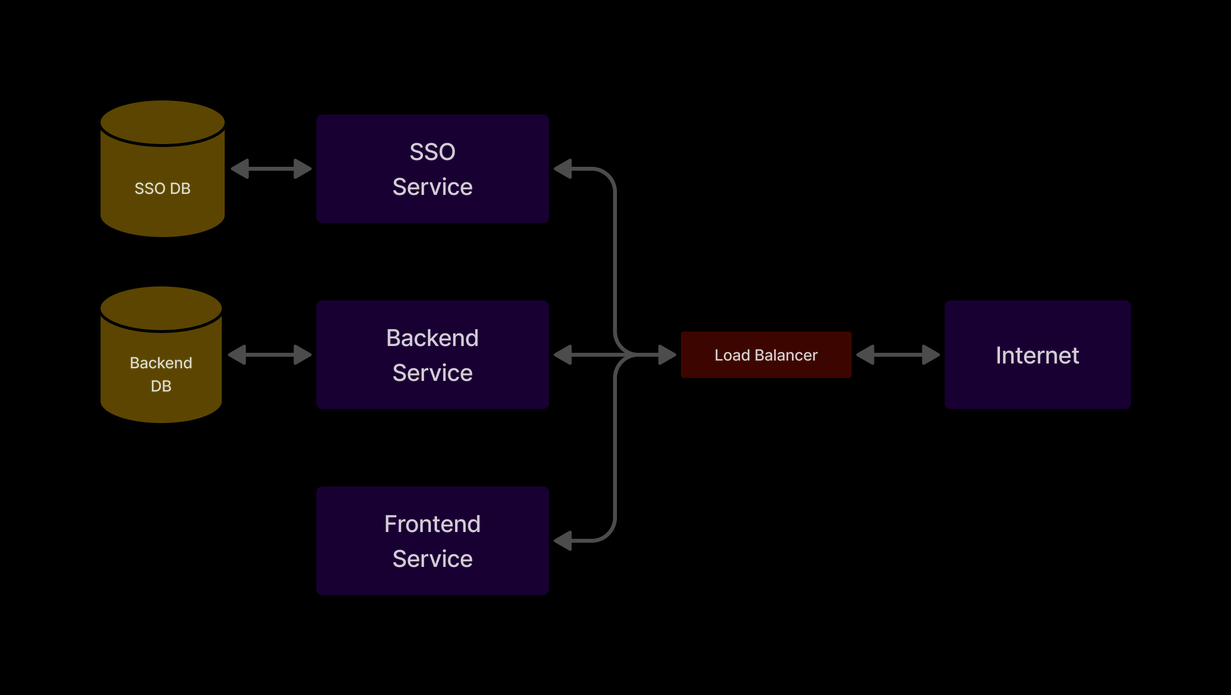
- Frontend (FE): This is the part of the website you interact with, where you buy IWAG event passes and manage your details.
- Backend (BE): This handles all the behind-the-scenes work, such as processing your payments and ensuring payments go through smoothly.
- Single Sign-On (SSO): This service manages your account, including registering, logging in, and updating your profile.
- Database (DB): This stores all the essential information, like your profile, transaction history, and event pass details.
When you use the website (like clicking the “Register Now” button), your request goes through a system called a Load Balancer (LB). Think of it as a traffic light that manages the flow of cars (your requests) to avoid jams. The Load Balancer directs requests to different servers so that no single server gets overwhelmed. This keeps everything running smoothly, even when there’s a lot of traffic.
Minute by Minute
Now that you have some context, let’s walk you through the events of that night, step by step:
-
19:45 (UTC+7): The tech team set up a “War Room” to monitor the Event Pass registration process. Members joined in person and remotely to keep a close eye on the servers.
-
20:00 (UTC+7): Users and staff began noticing issues: the website slowed significantly, showing “Internal Server Error (500)” and “Bad Gateway (502)” messages. It became almost impossible to load the checkout pages and pay for Event Passes.
-
20:20 (UTC+7): We identified the first major issue: database locking. The database was handling transactions one at a time in an overly strict mode, causing delays. A quick fix was applied to relax these rules.
-
20:35 (UTC+7): Despite the database fix, the 500 and 502 errors continued. Assuming heavy traffic was to blame, we scaled up both the frontend (FE) and backend (BE) services to handle more users. At this point, we decided to delay the Event Pass sales to 21:00 (UTC+7) to stabilize the system.
-
20:50 (UTC+7): With extra server power, the system seemed more stable, though the Load Balancer (LB) was still struggling. We prepared for the next sales window.
-
21:00-21:40 (UTC+7): As sales reopened, the 500 and 502 errors returned. The team scaled up the FE and BE services again while analyzing logs for deeper issues. The sales window was delayed twice, first to 21:30 (UTC+7) and then to 22:00 (UTC+7).
-
21:55 (UTC+7): The errors reappeared as traffic increased. This time, we decided to keep the registration open to collect more logs, which would help pinpoint the problem.
-
22:30 (UTC+7): A spike in requests to the single sign-on (SSO) service was identified. The system was being overwhelmed by repeated requests for “refresh tokens” (used to keep users logged in). We considered bypassing this process temporarily but instead chose to scale up the SSO provider to handle the load.
-
23:30 (UTC+7): Even after scaling up the SSO provider, the issue persisted. We concluded that the problem wasn’t just capacity but also how requests were being routed. The team decided to split the Load Balancer (LB) into two: one for BE instances and another for the SSO provider.
-
23:45 (UTC+7): Work began to separate the Load Balancer.
-
00:10 (UTC+7): The separation was complete. As a precaution, we logged out all users via the SSO provider’s admin panel to reduce further strain.
-
00:20 (UTC+7): After monitoring the system for 10 minutes, the errors stopped. All services were stable and back to normal.
What We Did to Fix It
Here are the key measures we took to resolve the issues:
-
Database Fixes: The transactions were made stricter after the incident of IWAG 2024, where Pearl passes were oversold, in hopes to prevent the possibility of duplicate transactions on other events. We adjusted transaction handling to be less strict to prevent the database from locking up.
-
Scaling Up Services:
- Increased the capacity of FE and BE instances to handle high demand.
- Boosted the SSO provider’s capacity to manage the surge in login-related requests.
-
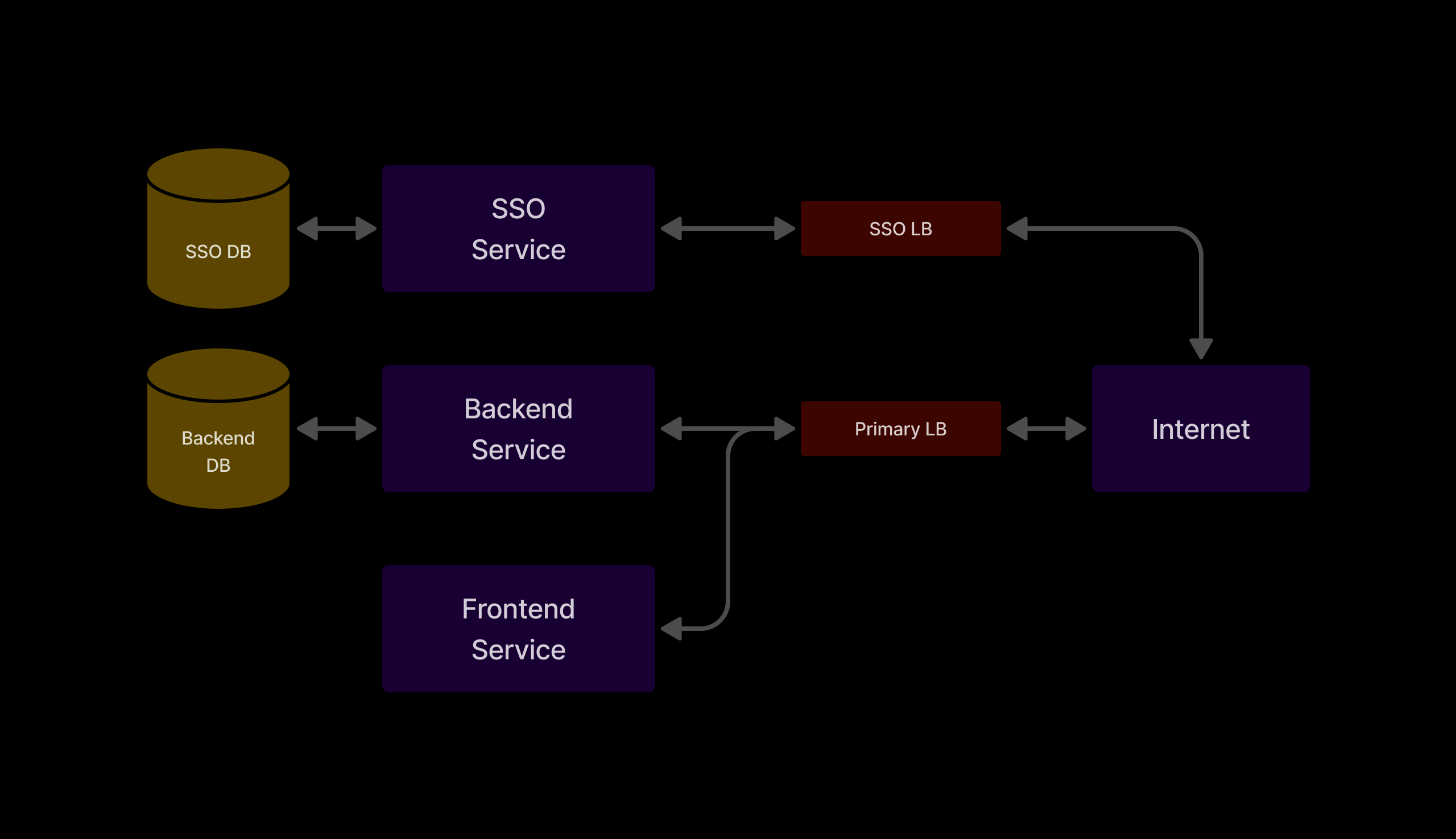
Load Balancer Adjustments: Separated the Load Balancer for BE and SSO services to manage traffic more efficiently.
-
Session Management: Logged out all users as a safety measure to ease the load on the SSO service.
After the changes made to the Load Balancer, our architecture changed slightly. Our simplified architecture diagram now looks like this:
How Logging In Works
To understand what went wrong, let’s take a brief look at how authentication (signing in and out) works.
Our single sign-on (SSO) provider uses OAuth 2.0, a widely-used standard for authenticating users. If you’ve ever clicked “Sign in with Google” on a website, you’ve used OAuth 2.0! It ensures users can log in securely without needing to re-enter credentials for every service.
Here’s a simplified explanation of how it works when you log into the Community website:
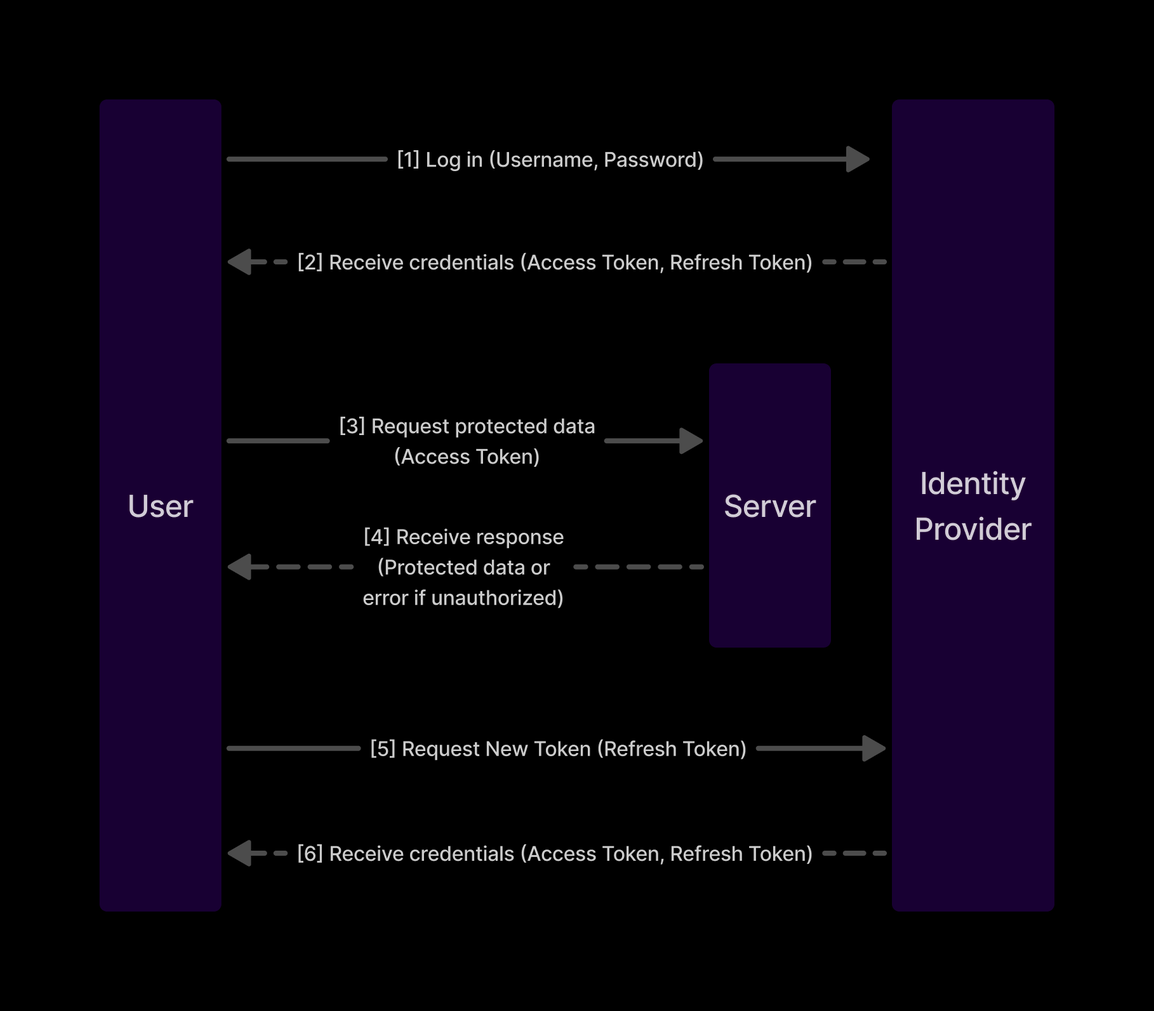
- You enter your credentials (like your email and password) on the login page.
- The Frontend (FE) sends these credentials to the SSO Provider.
- The SSO Provider verifies your credentials and sends back two important tokens:
- Access Token: Used to prove you’re logged in for specific actions (e.g., registering for an Event Pass).
- Refresh Token: Used to get a new Access Token without needing to log in again.
These tokens are really just a bunch of random numbers and character generated by the machines. With these tokens, you’re officially logged in and can perform actions on the website.
Access Tokens expire after some time for security reasons. Here’s how the system keeps your session active without asking you to log in again:
- When the Access Token expires, the FE sends the Refresh Token to the SSO Provider to request a new Access Token.
- The SSO Provider sends back both a new Access Token and a new Refresh Token.
- This process happens in the background, so you remain logged in seamlessly.
What Went Wrong
The issues stemmed from the Refresh Token flow, which is designed to keep users logged in. Here’s what went wrong:
-
SSO Overload:
- The SSO server was overwhelmed by a sudden surge in requests, primarily from users loading and refreshing the Event and checkout pages.
- It couldn’t handle all the requests and stopped responding properly.
-
Automatic Retrying:
- When the FE didn’t receive a response from the SSO, it retried the request automatically.
- This created a vicious cycle where failed requests kept adding more load to the already struggling SSO.
-
Token Invalidation:
- The SSO Provider started invalidating Refresh Tokens prematurely, which added another layer of issues.
- The FE unknowingly sent invalid Refresh Tokens in its retries, worsening the loop.
What We Learned
Here are the key takeaways to prevent such issues in the future:
-
Prioritize Scalability: Scaling up our systems were done manually, which can be overwhelming on a platform with highly-variable demand like Community. Investing in better infrastructure could help with easier scaling.
-
Improve Load Testing: While we have done some form of load testing before important events, there are parts where our load testing process could be improved to better replicate actual page load.
-
Longer-Lived Tokens: The access tokens were short-lived due to the immediate nature of our transactions. In our case, a little more leeway to when sessions expire will help reduce the load on our SSO provider.
-
Isolate High-Demand Services: Decoupling the Load Balancer for BE and SSO services ensured they didn’t compete for resources under high load, preventing cascading issues should one critical service fail.
-
Enhance Logging and Monitoring: We managed to catch our issues through request logs. Opening up access to our logging and monitoring tools to the rest of the tech team could help in early issue detection.
How This Influences Our Sponsor Tier Release
As we are wrapping up with the investigation and resolution from our systems, we want to instill the highest confidence on our attendees. We wanted to ensure that the system would be able to handle crush loads again in a controlled manner.
This is why we have decided to postpone the Pioneer and Guardian event passes to 11 January 2025, and in two batches, so we can monitor the behavior and ensure nothing else happens.
Going forward, our registration team will evaluate how best to release our coveted higher tier passes, in conjunction with the availability of our system.